Most organizations no longer struggle to collect data. They struggle to deliver it where it creates value. As analytics, security, compliance, and AI teams multiply their toolsets, a tangled web of point-to-point pipelines and duplicate feeds has become the limiting factor. Industry studies report that data teams spend 20–40% of their time on data management pipeline maintenance, and rework. That maintenance tax slows innovation, increases costs, and undermines the reliability of analytics.
When routing is elevated into the pipeline layer with flexibility and control, this calculus changes. Instead of treating routing as plumbing, enterprises can deliver the right data, in the right shape, to the right destination, at the right cost. This blog explores why flexible data routing and data management matters now, common pitfalls of legacy approaches, and how to design architectures that scale with analytics and AI.
Why Traditional Data Routing Holds Enterprises Back
For years, enterprises relied on simple, point-to-point integrations: a connector from each source to each destination. That worked when data mostly flowed into a warehouse or SIEM. But in today’s multi-tool, multi-cloud environments, these approaches create more problems than they solve — fragility, inefficiency, unnecessary risk, and operational overhead.
Pipeline sprawl
Every new destination requires another connector, script, or rule. Over time, organizations maintain dozens of brittle pipelines with overlapping logic. Each change introduces complexity, and troubleshooting becomes slow and resource intensive. Scaling up only multiplies the problem.
Data duplication and inflated costs
Without centralized data routing, the same stream is often ingested separately by multiple platforms. For example, authentication logs might flow to a SIEM, an observability tool, and a data lake independently. This duplication inflates ingestion and storage costs, while complicating governance and version control.
Vendor lock-in
Some enterprises route all data into a single tool, like a SIEM or warehouse, and then export subsets elsewhere. This makes the tool a de facto “traffic controller,” even though it was never designed for that role. The result: higher switching costs, dependency risks, and reduced flexibility when strategies evolve.
Compliance blind spots
Different destinations demand different treatments of sensitive data. Without flexible data routing, fields like user IDs or IP addresses may be inconsistently masked or exposed. That inconsistency increases compliance risks and complicates audits.
Engineering overhead
Maintaining a patchwork of pipelines consumes valuable engineering time. Teams spend hours fixing schema drift, rewriting scripts, or duplicating work for each new destination. That effort diverts resources from critical operations and delays analytics delivery.
The outcome is a rigid, fragmented data routing architecture that inflates costs, weakens governance, and slows the value of data management. These challenges persist because most organizations still rely on ad-hoc connectors or tool-specific exports. Without centralized control, data routing remains fragmented, costly, and brittle.
Principles of Flexible Data Routing
For years, routing was treated as plumbing. Data moved from point A to point B, and as long as it arrived, the job was considered done. That mindset worked when there were only one or two destinations to feed. It does not hold up in today’s world of overlapping analytics platforms, compliance stores, SIEMs, and AI pipelines.
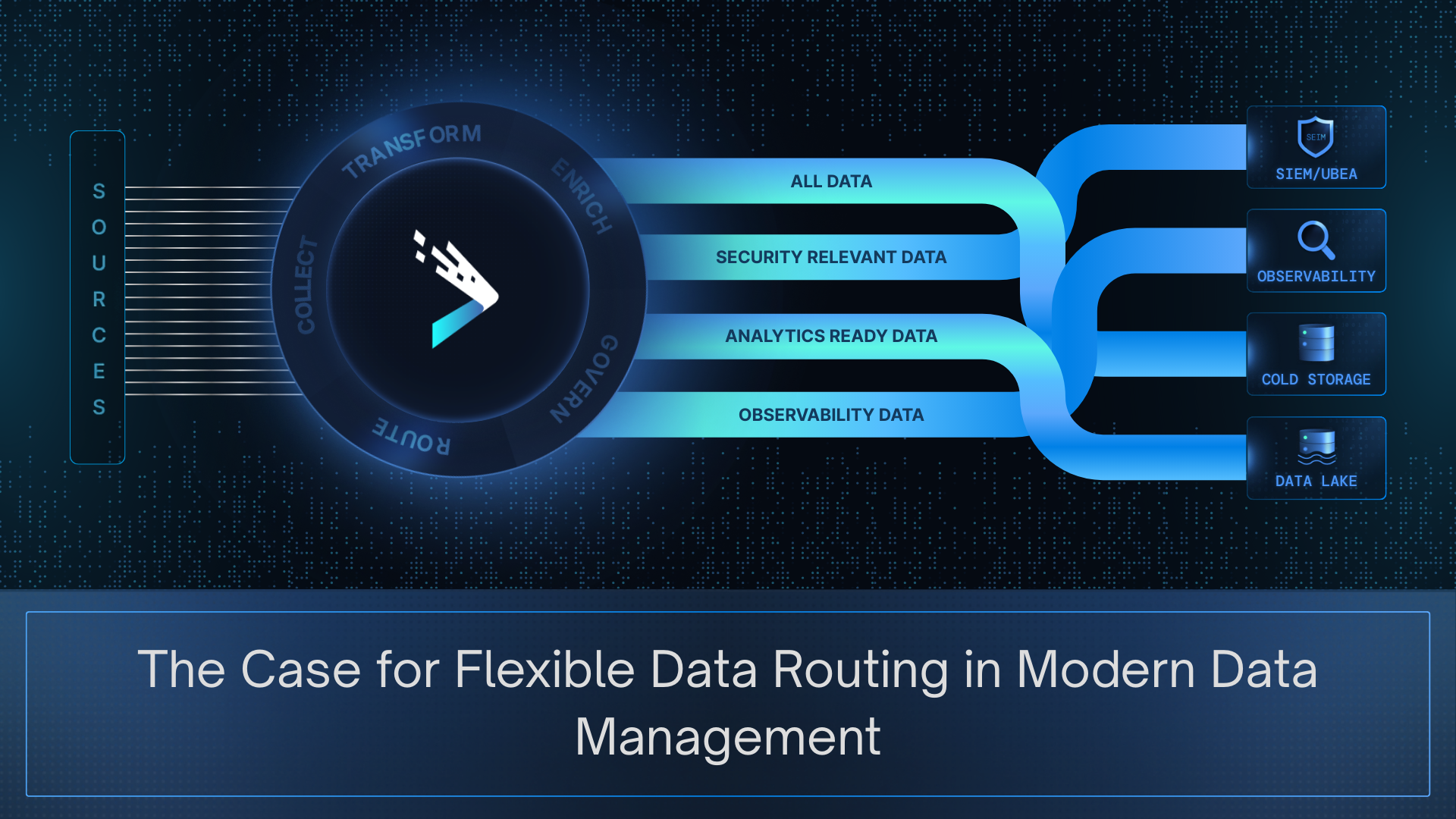
A modern data pipeline management platform introduces routing as a control layer. The question is no longer “can we move the data” but “how should this data be shaped, governed, and delivered across different consumers.” That shift requires a few guiding principles.
Collection should happen once, not dozens of times. Distribution should be deliberate, with each destination receiving data in the format and fidelity it needs. Governance should be embedded in the pipeline layer so that policies drive what is masked, retained, or enriched. Most importantly, routing must remain independent of any single tool. No SIEM, warehouse, or observability platform should define how all other systems receive their data.
These principles are less about mechanics than about posture. A smart, flexible, data routing architecture ensures efficiency at scale, governance and contextualized data, and automation. Together they represent an architectural stance that data deserves to travel with intent, shaped and delivered according to value.
The Benefits of Flexible, Smart, and AI-Enabled Routing
When routing is embedded in centralized data pipelines rather than bolted on afterward, the advantages extend far beyond cost. Flexible data routing, when combined with smart policies and AI-enabled automation, resolves the bottlenecks that plague legacy architectures and enables teams to work faster, cleaner, and with more confidence.
Streamlined operations
A single collection stream can serve multiple destinations simultaneously. This removes duplicate pipelines, reduces source load, and simplifies monitoring. Data moves through one managed layer instead of a patchwork, giving teams more predictable and efficient operations.
Agility at scale
New destinations no longer mean hand-built connectors or point-to-point rewiring. Whether it is an additional SIEM, a lake house in another cloud, or a new analytics platform, routing logic adapts quickly without forcing costly rebuilds or disrupting existing flows.
Data consistency and reliability
A centralized pipeline layer applies normalization, enrichment, and transformation uniformly. That consistency ensures investigations, queries, and models all receive structured data they can trust, reducing errors and making cross-platform analytics.
Compliance assurance
Policy-driven routing within the pipeline allows sensitive fields to be masked, transformed, or redirected as required. Instead of piecemeal controls at the tool level, compliance is enforced upstream, reducing risk of exposure and simplifying audits.
AI and analytics readiness
Well-shaped, contextual telemetry can be routed into data lakes or ML pipelines without additional preprocessing. The pipeline layer becomes the bridge between raw telemetry and AI-ready datasets.
Together, these benefits elevate routing from a background function to a strategic enabler. Enterprises gain efficiency, governance, and the agility to evolve their architectures as data needs grow.
Real-World Strategies and Use Cases
Flexible routing proves its value most clearly in practice. The following scenarios show how enterprises apply it to solve everyday challenges that brittle pipelines cannot handle:
Security + analytics dual routing
Authentication and firewall logs can flow into a SIEM for detection while also landing in a data lake for correlation and model training. Flexible data routing makes dual delivery possible, and smart routing ensures each destination receives the right format and context.
Compliance-driven routing
Personally identifiable information can be masked before reaching a SIEM but preserved in full within a compliant archive. Smart routing enforces policies upstream, ensuring compliance without slowing operations.
Performance optimization
Observability platforms can receive lightweight summaries to monitor uptime, while full-fidelity logs are routed into analytics systems for deep investigation. Flexible routing splits the streams, while AI-enabled capabilities can help tune flows dynamically as needs change.
AI/ML pipelines
Machine learning workloads demand structured, contextual data. With AI-enabled routing, telemetry is normalized and enriched before delivery, making it immediately usable for model training and inference.
Hybrid and multi-cloud delivery
Enterprises often operate across multiple regions and providers. Flexible routing ensures a single ingest stream can be distributed across clouds, while smart routing applies governance rules consistently and AI-enabled features optimize routing for resilience and compliance.
Building for the future with Flexible Data Routing
The data ecosystem is expanding faster than most architectures can keep up with. In the next few years, enterprises will add more AI pipelines, adopt more multi-cloud deployments, and face stricter compliance demands. Each of these shifts multiplies the number of destinations that need data and the complexity of delivering it reliably.
Flexible data routing offers a way forward enabling multi-destination delivery. Instead of hardwired connections or duplicating ingestion, organizations can ingest once and distribute everywhere, applying the right policies for each destination. This is what makes it possible to feed SIEM, observability, compliance, and AI platforms simultaneously without brittle integrations or runaway costs.
This approach is more than efficiency. It future-proofs data architectures. As enterprises add new platforms, shift workloads across clouds, or scale AI initiatives, multi-destination routing absorbs the change without forcing rework. Enterprises that establish this capability today are not just solving immediate pain points; they are creating a foundation that can absorb tomorrow’s complexity with confidence.
From Plumbing to Strategic Differentiator
Enterprises can’t step into the future with brittle, point-to-point pipelines. As data environments expand across clouds, platforms, and use cases, routing becomes the factor that decides whether architectures scale with confidence or collapse under their own weight. A modern routing layer isn’t optional anymore; it’s what holds complex ecosystems together.
With DataBahn, flexible data routing is part of an intelligent data layer that unifies collection, parsing, enrichment, governance, and automation. Together, these capabilities cut noise, prevent duplication, and deliver contextual data for every destination. The outcome is data management that flows with intent: no duplication, no blind spots, no wasted spend, just pipelines that are faster, cleaner, and built to last.



.png)


.jpg)

.png)
.png)


.png)

